-
[Tensorflow, Keras] LSTM 실습 _ 아마존 리뷰 감성 분석(NLP)IT/AI 2022. 10. 20. 01:55
LSTM을 사용하여 텍스트의 긍정/부정 감성 분석을 하는 간단한 예제를 학습해봅니다.
데이터셋은 Tensorflow에서 제공하는 Amazon 고객 리뷰(amazon_us_reviews) 데이터셋 중 디지털 소프트웨어 제품 부문의 고객 리뷰에 대한 텍스트 감성 분석을 해보겠습니다.
Tensorflow에서 제공하는 다양한 데이터셋은 "https://www.tensorflow.org/datasets/catalog/overview"에서 확인 가능하며, 음성, 이미지, 텍스트 등 다양한 소스 데이터를 제공합니다.
데이터셋에 관한 정보를 미리 확인하고 싶으시면 아래의 그림을 참고바랍니다.
이번 예제에서 사용할 데이터 셋은 "amazon_us_reviews/Digital_Software_v1_00" 입니다.
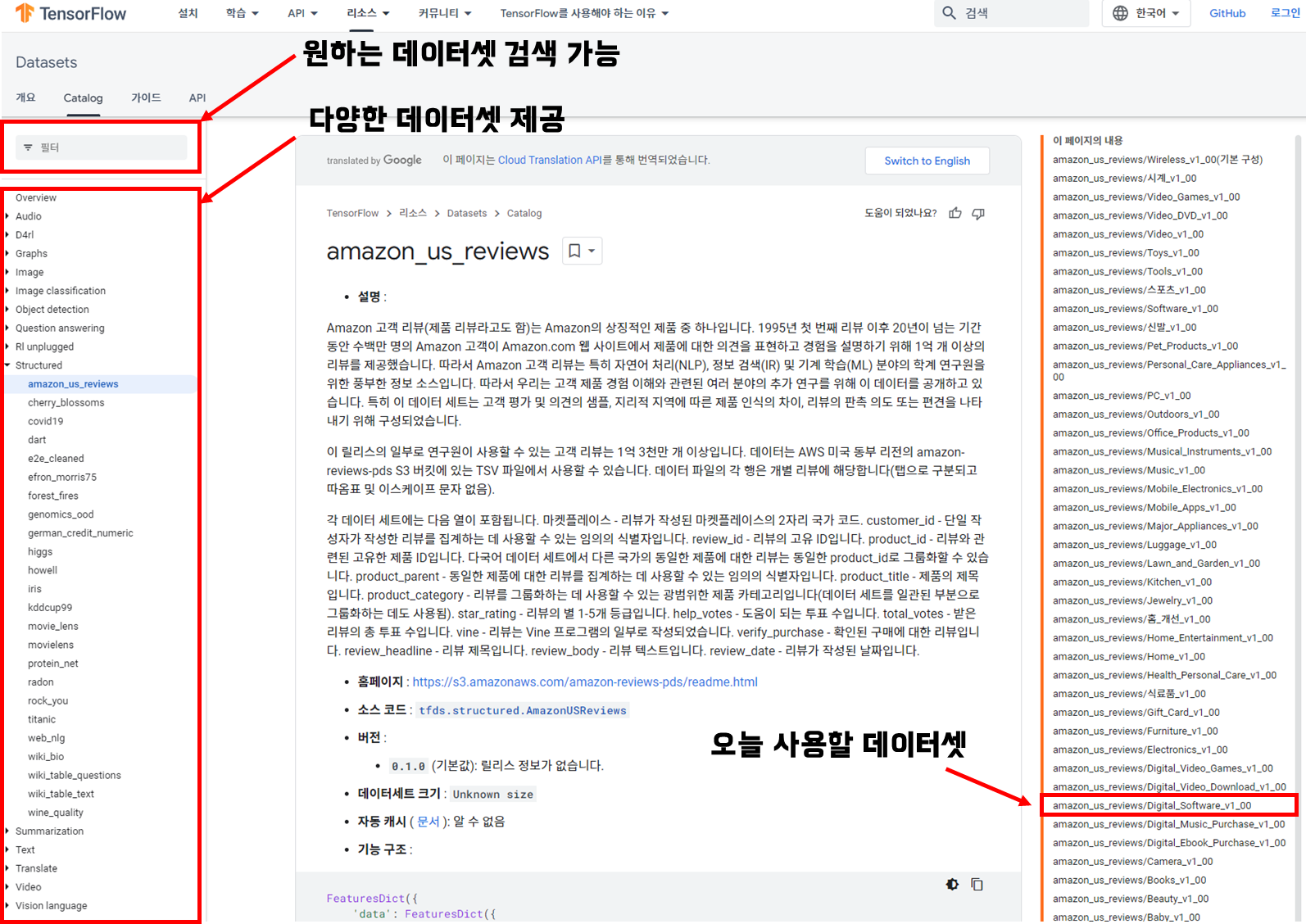
TensorFlow datasets Catalog
Step 01. Import Library
In [ 1 ]: 학습에 필요한 라이브러리를 미리 import 합니다.import tensorflow as tf import tensorflow_datasets as tfds from tensorflow.keras.preprocessing.text import Tokenizer from tensorflow.keras.preprocessing.sequence import pad_sequences import matplotlib.pyplot as plt import numpy as npStep 02. Dataset 불러오기
In [ 2 ]: tfds(tensorflow datasets)로부터 데이터셋을 불러옵니다.# Tensorflow로 부터 데이터셋을 불러오기 # with_info = True 설정 시, 데이터셋에 관한 정보도 받아 올 수 있습니다. dataset, info = tfds.load(name='amazon_us_reviews/Digital_Software_v1_00', with_info=True)In [ 3 ]: 데이터셋 로드 시에 정보를 받아온 info 변수로 데이터셋 정보를 확인합니다.# 데이터셋 정보 확인하기 infoOut[ 3 ]: 데이터셋의 정보를 확인하며 어떤 정보가 필요할지 미리 결정 할 수 있습니다.이번 학습은 리뷰를 통한 감정 분석(부정 / 긍정)을 위한 실습입니다.
따라서, 리뷰 내용인 "review_body"와 평점인 "star_rating"만을 활용할 것입니다. In [ 4 ]: Tensorflow dataset에서 실제 데이터는 splits 부분에 명시된 키로 데이터가 분할되어 있습니다.'train'과 'test' 각각 분할된 데이터셋도 있지만, 이번 데이터셋은 'train'으로만 분할되어 있습니다.
In [ 4 ]: Tensorflow dataset에서 실제 데이터는 splits 부분에 명시된 키로 데이터가 분할되어 있습니다.'train'과 'test' 각각 분할된 데이터셋도 있지만, 이번 데이터셋은 'train'으로만 분할되어 있습니다.# Split된 데이터 확인하기 dataset['train']Out[ 4 ]: 현재 데이터셋은 이중 딕셔너리 구조로 되어있고, 내부 데이터 목록을 확인할 수 있습니다.<PrefetchDataset element_spec={'data': {'customer_id': TensorSpec(shape=(), dtype=tf.string, name=None), 'helpful_votes': TensorSpec(shape=(), dtype=tf.int32, name=None), 'marketplace': TensorSpec(shape=(), dtype=tf.string, name=None), 'product_category': TensorSpec(shape=(), dtype=tf.string, name=None), 'product_id': TensorSpec(shape=(), dtype=tf.string, name=None), 'product_parent': TensorSpec(shape=(), dtype=tf.string, name=None), 'product_title': TensorSpec(shape=(), dtype=tf.string, name=None), 'review_body': TensorSpec(shape=(), dtype=tf.string, name=None), 'review_date': TensorSpec(shape=(), dtype=tf.string, name=None), 'review_headline': TensorSpec(shape=(), dtype=tf.string, name=None), 'review_id': TensorSpec(shape=(), dtype=tf.string, name=None), 'star_rating': TensorSpec(shape=(), dtype=tf.int32, name=None), 'total_votes': TensorSpec(shape=(), dtype=tf.int32, name=None), 'verified_purchase': TensorSpec(shape=(), dtype=tf.int64, name=None), 'vine': TensorSpec(shape=(), dtype=tf.int64, name=None)}}>
Step 03. Tensorflow 데이터셋을 데이터 프레임으로 변환
In [ 5 ]: tfds의 .as_dataframe 메서드를 사용해서 데이터셋을 데이터프레임으로 변환합니다.# Tensorflow에서 제공하는 데이터셋을 데이터 프레임 형태로 변환하기 df = tfds.as_dataframe(dataset['train']) df.head() # df['data/star_rating'].head(10) # df['data/review_body'].head(10)Out[ 5 ]: In [ 6 ]: 필요한 정보만 추출하기 위해 'review_body'와 'star_rating' 칼럼만 추출해서 새 데이터프레임을 만듭니다.
In [ 6 ]: 필요한 정보만 추출하기 위해 'review_body'와 'star_rating' 칼럼만 추출해서 새 데이터프레임을 만듭니다.# 'review_body'와 'star_rating' columns로 새로운 데이터 프레임 생성하기 new_df = df[['data/review_body', 'data/star_rating']] new_dfOut[ 6 ]: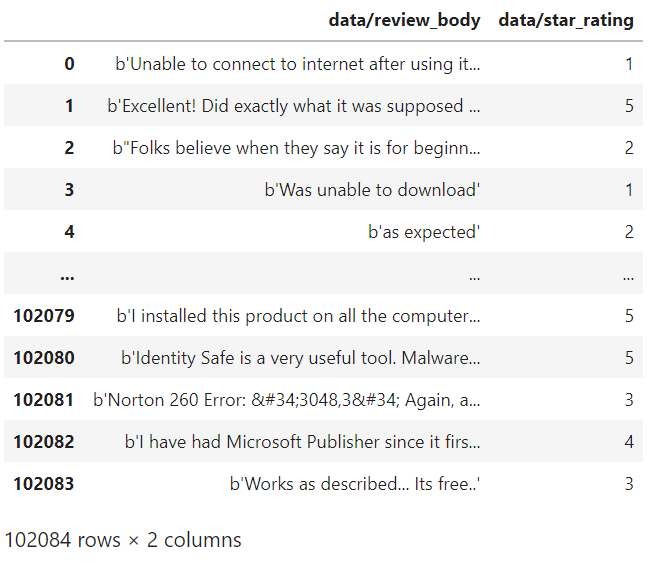
3-1. 긍정/부정 이진 분류를 위해 평점 1-3까지는 0으로 변환, 4-5는 1로 변환
3-1 과정과 3-2 과정은 train dataset과 test dataset을 분할한 후 진행해도 무관하지만
편의를 위해 데이터를 분할하기 전 미리 진행합니다.In [ 7 ]: star_rating column의 값을 변경합니다.new_df["data/star_rating"] = np.where(new_df["data/star_rating"] <= 3, 0, 1) # new_df.loc[new_df["data/star_rating"] <= 3, "data/star_rating"] = 0 new_dfOut[ 7 ]:
 3-2. review_body의 data type 변환 (byte -> String)In [ 8 ]:
3-2. review_body의 data type 변환 (byte -> String)In [ 8 ]:Out[7]을 보면 review_body의 값들 앞에 b'가 붙은걸 확인할 수 있습니다.
이는 해당 값들이 byte로 인코딩되어 있다는 의미이고, [byte].decode('encoding 방식')을 통해 원래의 string으로 변환 가능합니다.new_df["data/review_body"] = [sentence.decode('utf-8') for sentence in new_df["data/review_body"]] new_dfOut[ 8 ]: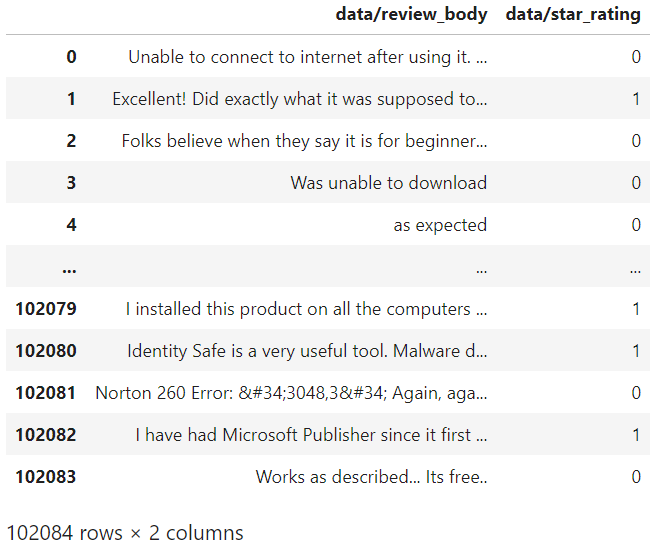
Step 04. Train & Test 데이터셋 분할 및 정답 레이블 분할(train_Y, test_Y)
In [ 9 ]: 80% 는 Train dataset으로 20%는 Test dataset으로 사용할 예정# Train , Test dataset split을 위한 변수 설정 (Train = 0.8 : Test = 0.2) num_ex = 102084 slicing = int(0.8*num_ex) print(slicing) # Train dataset & Test dataset 분리 train_df = new_df.iloc[:slicing, :] test_df = new_df.iloc[slicing:, :] # test_df.reset_index() print(f"Train dataset's shape : {train_df.shape}") print(f"Test dataset's shape : {test_df.shape}")Out[ 9 ]:
81667 Train dataset's shape : (81667, 2) Test dataset's shape : (20417, 2)In [ 10 ]: star_rating 값을 np.array로 변환 (모델 학습을 위한 변환)# 학습을 위한 정답 데이터(Y) 만들기 train_Y = np.array(train_df['data/star_rating']) test_Y = np.array(test_df['data/star_rating']) print(f"train_Y shape : {train_Y.shape}") print(f"test_Y shape : {test_Y.shape}")Out[ 10 ]:
train_Y shape : (81667,) test_Y shape : (20417,)Step 05. Text 정제
5-1. Text 정제를 위해 데이터프레임의 review body부분을 list로 변환
In [ 11 ]: Dataframe의 review_body 부분을 list로 변환하여 text 정제를 진행# trian_df , test_df에서 각각 review body 부분을 리스트로 변환 train_text_X = train_df['data/review_body'].values.tolist() test_text_X = test_df['data/review_body'].values.tolist() print(len(train_text_X)) print(type(train_text_X)) print(train_text_X[0]) print(test_text_X[0])Out[ 11 ]:
81667 <class 'list'> Unable to connect to internet after using it. It takes over night to run. After it restart, I was unable to connect to internet using Ethernet cable. I have to restore the computer. Since I've upgraded to Windows 7, I've been looking for a replacement for GoBack. Nothing out there quite replaced it, and RollBack doesn't fully replace all it's functionality either, but it's the closest I've found. I've set it up to do a snapshot every 60 minutes (GoBack did snapshots in realtime) which is more that adequate for my needs (you can choose to have a snapshot every minute if you want).<br /><br />So far I can't see any effect on system performance with it running. Seems to have little impact. I did have one mishap on the install. For some reason it kept failing when I selected "typical" install. I tried "custom" and then had no problem.5-2. 정규표현식 함수 정의
In [ 12 ]: 불필요한 입력이나 기호 등을 제거하기 위해 정규표현식으로 데이터를 정제합니다.# train 데이터의 입력(X)에 대한 정제(Cleaning) import re # From https://github.com/yoonkim/CNN_sentence/blob/master/process_data.py def clean_str(string): string = re.sub(r"[^가-힣A-Za-z0-9(),!?\'\`]", " ", string) string = re.sub(r"\'s", " \'s", string) string = re.sub(r"\'ve", " \'ve", string) string = re.sub(r"n\'t", " n\'t", string) string = re.sub(r"\'re", " \'re", string) string = re.sub(r"\'d", " \'d", string) string = re.sub(r"\'ll", " \'ll", string) string = re.sub(r",", " , ", string) string = re.sub(r"!", " ! ", string) string = re.sub(r"\(", " \( ", string) string = re.sub(r"\)", " \) ", string) string = re.sub(r"\?", " \? ", string) string = re.sub(r"\s{2,}", " ", string) string = re.sub(r"\'{2,}", "\'", string) string = re.sub(r"\'", "", string) return string.lower()5-3. 정규표현식 적용
In [ 13 ]:train_text_X = [clean_str(sentence) for sentence in train_text_X] test_text_X = [clean_str(sentence) for sentence in test_text_X]5-4. 띄어쓰기 단위로 단어 분리
In [ 14 ]:# 문장을 띄어쓰기 단위로 단어 분리 (Train data) train_sentences = [sentence.split(' ') for sentence in train_text_X] for i in range(5): print(train_sentences[i]) print("\n") # 문장을 띄어쓰기 단위로 단어 분리 (Train data) test_sentences = [sentence.split(' ') for sentence in test_text_X] for i in range(5): print(test_sentences[i])Out[ 14 ]:
['unable', 'to', 'connect', 'to', 'internet', 'after', 'using', 'it', 'it', 'takes', 'over', 'night', 'to', 'run', 'after', 'it', 'restart', ',', 'i', 'was', 'unable', 'to', 'connect', 'to', 'internet', 'using', 'ethernet', 'cable', 'i', 'have', 'to', 'restore', 'the', 'computer', ''] ['excellent', '!', 'did', 'exactly', 'what', 'it', 'was', 'supposed', 'to', ',', 'and', 'user', 'friendly', 'as', 'well', '!', ''] ['folks', 'believe', 'when', 'they', 'say', 'it', 'is', 'for', 'beginners', 'if', 'you', 've', 'ever', 'gotten', 'wet', 'you', 'probably', 'already', 'know', 'as', 'much', 'as', 'this', 'app', 'will', 'teach', ''] ['was', 'unable', 'to', 'download'] ['as', 'expected'] ['since', 'i', 've', 'upgraded', 'to', 'windows', '7', ',', 'i', 've', 'been', 'looking', 'for', 'a', 'replacement', 'for', 'goback', 'nothing', 'out', 'there', 'quite', 'replaced', 'it', ',', 'and', 'rollback', 'does', 'nt', 'fully', 'replace', 'all', 'it', 's', 'functionality', 'either', ',', 'but', 'it', 's', 'the', 'closest', 'i', 've', 'found', 'i', 've', 'set', 'it', 'up', 'to', 'do', 'a', 'snapshot', 'every', '60', 'minutes', '\\(', 'goback', 'did', 'snapshots', 'in', 'realtime', '\\)', 'which', 'is', 'more', 'that', 'adequate', 'for', 'my', 'needs', '\\(', 'you', 'can', 'choose', 'to', 'have', 'a', 'snapshot', 'every', 'minute', 'if', 'you', 'want', '\\)', 'br', 'br', 'so', 'far', 'i', 'ca', 'nt', 'see', 'any', 'effect', 'on', 'system', 'performance', 'with', 'it', 'running', 'seems', 'to', 'have', 'little', 'impact', 'i', 'did', 'have', 'one', 'mishap', 'on', 'the', 'install', 'for', 'some', 'reason', 'it', 'kept', 'failing', 'when', 'i', 'selected', '34', 'typical', '34', 'install', 'i', 'tried', '34', 'custom', '34', 'and', 'then', 'had', 'no', 'problem', ''] ['code', 'work', 'nice', 'and', 'fast', ',', 'no', 'issues'] ['i', 'd', 'never', 'used', 'quickbooks', 'in', 'any', 'form', 'before', ',', 'and', 'found', 'this', 'relatively', 'quick', 'to', 'learn', 'and', 'get', 'going', ',', 'even', 'with', 'very', 'little', 'accounting', 'experience', 'however', ',', 'i', 'am', 'disappointed', 'that', 'mac', 'users', 'get', 'short', 'changed', '\\(', 'as', 'usual', '\\)', 'in', 'the', 'feature', 'department', ',', 'as', 'compared', 'to', 'the', 'windows', 'versions', ''] ['we', 'have', 'used', 'avast', 'antivirus', 'free', 'version', 'for', 'quite', 'a', 'few', 'years', 'and', 'we', 'really', 'love', 'it', 'we', 'have', 'nt', 'had', 'any', 'trouble', 'with', 'viruses', 'for', 'years', ''] ['every', 'year', ',', 'we', 'order', 'the', 'turbo', 'tax', ',', 'and', 'it', 'alway', 'have', 'a', 'high', 'level', 'of', 'success', 'thankyou', 'james', '']In [ 15 ]: 문장에서 몇 개의 단어까지 입력으로 넣을지 결정하기 위해 문장별 단어 수를 체크합니다.# 각 문장의 단어 길이 확인 (Train) import matplotlib.pyplot as plt sentence_len = [len(sentence) for sentence in train_sentences] sentence_len.sort() plt.plot(sentence_len) plt.show() # 81667 * 0.8 = 65334 print(sum([int(l<=100) for l in sentence_len]))
Out[ 15 ]: 전체 문장의 80% 가량이 100개 이하의 단어를 사용함으로 100개의 단어만 사용하도록 합니다.
650635-5. 최대 100개 단어로 문장 자르기 + 한 단어 최대 글자 수 10개로 제한
In [ 16 ]: 최대 단어 수 제한 및 최대 단어 글자 수 제한# 단어 정제 및 문장 길이 줄임 (Train) sentences_new = [] for sentence in train_sentences: # 각 문장의 단어 개수를 100개 까지의 제한하고 각 단어를 10글자로 제한 sentences_new.append([word[:10] for word in sentence][:100]) train_sentences = sentences_new for i in range(5): print(train_sentences[i])현재 데이터에는 나타나지 않았지만 단어의 글자 수를 10개로 제한하면 "insteresting" -> "interestin"이 됩니다.전체 단어를 다 표현하지 않아도 학습 시 해당 단어가 가진 의미가 어느 정도는 보존되기 때문에 적절한 길이로 단어를 자르면 여러 개의 단어에 분산될 수 있는 의미를 하나로 모을 수 있게 됩니다.예를 들어, "스파이더맨", "스파이더맨이", "스파이더맨을" 등의 단어가 나온다고 가정할 때, 앞에서부터 5글자로 자르면 모두 "스파이더맨"이라는 한 단어가 됩니다.Out[ 16 ]:
['unable', 'to', 'connect', 'to', 'internet', 'after', 'using', 'it', 'it', 'takes', 'over', 'night', 'to', 'run', 'after', 'it', 'restart', ',', 'i', 'was', 'unable', 'to', 'connect', 'to', 'internet', 'using', 'ethernet', 'cable', 'i', 'have', 'to', 'restore', 'the', 'computer', ''] ['excellent', '!', 'did', 'exactly', 'what', 'it', 'was', 'supposed', 'to', ',', 'and', 'user', 'friendly', 'as', 'well', '!', ''] ['folks', 'believe', 'when', 'they', 'say', 'it', 'is', 'for', 'beginners', 'if', 'you', 've', 'ever', 'gotten', 'wet', 'you', 'probably', 'already', 'know', 'as', 'much', 'as', 'this', 'app', 'will', 'teach', ''] ['was', 'unable', 'to', 'download'] ['as', 'expected']In [ 17 ]: Test 데이터에도 동일하게 적용# 단어 정제 및 문장 길이 줄임 (Test) sentences_new = [] for sentence in test_sentences: sentences_new.append([word[:10] for word in sentence][:100]) sentences = sentences_new # for i in range(5): # print(sentences[i])5-6. Tokenizer와 pad_seequences를 사용해 문장 전처리
In [ 18 ]:Tokenizer는 데이터에 출현하는 모든 단어의 개수를 세고 빈도수로 정렬을 해줍니다.
이 때, num_words에 지정된 만큼만 숫자로 반환하고, 나머지는 0으로 반환합니다.
fit_on_texts 메서드를 통해 원하는 text datasets를 처리 가능하며,
texts_to_sequences 메서드로 각 단어는 index(number)로 변환됩니다.
pad_sequences는 단어가 없는 반 부분에 padding을 넣는 역할을 합니다.# Tokenizer와 pad_sequences를 사용한 문장 전처리 (Train) # tokenizer setting tokenizer = Tokenizer(num_words=30000) # train_sentences를 tokenizer에 대입 tokenizer.fit_on_texts(train_sentences) # tokenizer에 의해 구해진 단어의 index로 train_X 생성 train_X = tokenizer.texts_to_sequences(train_sentences) # 단어가 없는 부분이나 tokenizer num_words에 속하지 못한 단어 부분에 패딩을 넣음 train_X = pad_sequences(train_X, padding='post') print(train_X[:5])Out[ 18 ]:[[ 542 3 796 3 258 80 54 6 6 465 113 1731 3 286 80 6 1410 5 1 17 542 3 796 3 258 54 8044 2686 1 14 3 1199 2 69 9 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 276 22 71 565 77 6 17 760 3 5 4 124 325 27 96 22 9 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [1370 553 67 45 263 6 10 8 2553 55 18 81 253 818 8045 18 506 361 187 27 104 27 11 333 62 2312 9 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 17 542 3 51 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 27 470 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]In [ 19 ]: Test 데이터에도 똑같이 처리를 합니다.# Tokenizer와 pad_sequences를 사용한 문장 전처리 (Test) # train_sentences로 fit된 tokenizer 사용 test_X = tokenizer.texts_to_sequences(sentences) test_X = pad_sequences(test_X, padding='post')In [ 20 ]:# Tokenizer의 동작 확인 print(tokenizer.index_word[19999]) print(tokenizer.index_word[29999]) temp = tokenizer.texts_to_sequences(['repetative', 'inital', 'apple', 'chonchon']) print(temp) temp = pad_sequences(temp, padding='post') print(temp)Out [ 20 ]:
repetative # 19999번째 index의 단어 inital # 29999번째 index의 단어 # apple의 index는 850이고 chonchon의 index는 없습니다. -> 30000개의 단어에 속하지 못함 [[19999], [29999], [850], []] [[19999] [29999] [ 850] [ 0]]
Step 06. Model 정의 및 학습
In [ 21 ]: Embedding 레이어와 LSTM 레이어 Dense 레이어를 차례대로 쌓아줍니다.Embedding 레이어에서 30000은 tokenizer 선언 시 결정한 num_words의 수이고,
400은 해당 30000개의 단어를 몇차원의 벡터로 변환할 지 결정하는 인자입니다.
즉, 30000개의 단어를 400차원의 벡터로 임베딩을 하겠다는 말입니다.
input_length는 Embedding 레이어에 입력의 크기(차원)이며, 앞서 100개의 단어로 자른 것을 의미합니다.
LSTM 레이어에서 units은 은닉 값 또는 출력 값(Hidden State value)의 차원을 정하는 인자입니다.
긍정/부정 이진 분류를 위한 모델임으로 Dense 레이어의 출력은 2가 됩니다.# LSTM 레이어를 사용한 모델 정의 model = tf.keras.Sequential([ tf.keras.layers.Embedding(30000, 400, input_length=100), tf.keras.layers.LSTM(units=50), tf.keras.layers.Dense(2, activation='softmax') ]) model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) model.summary()Out [ 21 ]:
Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding_1 (Embedding) (None, 100, 400) 12000000 lstm_1 (LSTM) (None, 50) 90200 dense_1 (Dense) (None, 2) 102 ================================================================= Total params: 12,090,302 Trainable params: 12,090,302 Non-trainable params: 0 _________________________________________________________________In [ 22 ]:# 모델 학습 history = model.fit(train_X, train_Y, epochs=5, batch_size=128, validation_split=0.2)Output [ 22 ]:
Epoch 1/5 511/511 [==============================] - 16s 17ms/step - loss: 0.6130 - accuracy: 0.6771 - val_loss: 0.5472 - val_accuracy: 0.7546 Epoch 2/5 511/511 [==============================] - 10s 19ms/step - loss: 0.5037 - accuracy: 0.7841 - val_loss: 0.4743 - val_accuracy: 0.8053 Epoch 3/5 511/511 [==============================] - 9s 17ms/step - loss: 0.4795 - accuracy: 0.7662 - val_loss: 0.4404 - val_accuracy: 0.8223 Epoch 4/5 511/511 [==============================] - 8s 16ms/step - loss: 0.3030 - accuracy: 0.8784 - val_loss: 0.3081 - val_accuracy: 0.8752 Epoch 5/5 511/511 [==============================] - 8s 16ms/step - loss: 0.2338 - accuracy: 0.9114 - val_loss: 0.3083 - val_accuracy: 0.8722In [ 23 ]: 모델 학습 결과 시각화# 모델 학습 결과 확인 import matplotlib.pyplot as plt plt.figure(figsize=(12, 4)) plt.subplot(1, 2, 1) plt.plot(history.history['loss'], 'b-', label='loss') plt.plot(history.history['val_loss'], 'r--', label='val_loss') plt.xlabel('Epoch') plt.legend() plt.subplot(1, 2, 2) plt.plot(history.history['accuracy'], 'g-', label='accuracy') plt.plot(history.history['val_accuracy'], 'k--', label='val_accuracy') plt.xlabel('Epoch') plt.ylim(0.7, 1) plt.legend() plt.show()Output [ 23 ]: Epoch이 진행될 수록 Loss 값과 Val_loss 값 모두 감소하고 Accuracy도 상승함으로 학습이 꽤나 잘 됐다는 것을 알 수 있습니다.
Epoch이 진행될 수록 Loss 값과 Val_loss 값 모두 감소하고 Accuracy도 상승함으로 학습이 꽤나 잘 됐다는 것을 알 수 있습니다.Step 07. 평가
In [ 24 ]: Test 데이터로 모델을 평가하도록 합니다.model.evaluate(test_X, test_Y, verbose=0)Out[ 24 ]: 약 87.3% 의 정확도로 val_accuracy와 유사합니다.[0.30422443151474, 0.8734387755393982]In [ 25 ]: 임의로 만든 문장으로 모델 성능을 확인해보도록 합니다.# 임의의 문장 감성 분석 결과 확인 test_sentence = 'That was sleepy but very fun and excellent' test_sentence = test_sentence.split(' ') test_sentences = [] now_sentence = [] for word in test_sentence: now_sentence.append(word) test_sentences.append(now_sentence[:]) test_X_1 = tokenizer.texts_to_sequences(test_sentences) test_X_1 = pad_sequences(test_X_1, padding='post', maxlen=100) prediction = model.predict(test_X_1) for idx, sentence in enumerate(test_sentences): print(sentence) print(prediction[idx])Out[ 25 ]:
1/1 [==============================] - 0s 19ms/step ['That'] [0.10145491 0.898545 ] ['That', 'was'] [0.13440078 0.8655993 ] ['That', 'was', 'sleepy'] [0.7159861 0.28401396] ['That', 'was', 'sleepy', 'but'] [0.78960997 0.21038999] ['That', 'was', 'sleepy', 'but', 'very'] [0.81772065 0.1822793 ] ['That', 'was', 'sleepy', 'but', 'very', 'fun'] [0.70731467 0.29268527] ['That', 'was', 'sleepy', 'but', 'very', 'fun', 'and'] [0.58465004 0.41534996] ['That', 'was', 'sleepy', 'but', 'very', 'fun', 'and', 'excellent'] [0.03179764 0.96820235]왼쪽이 부정 리뷰일 확률 (star_rating : 1~3) 오른쪽이 긍정 리뷰일 확률 (star_rating : 4~5)입니다.'excellent'라는 단어가 나오기 전까지는 부정 확률이 앞서다가 'excellent' 출현 후 긍정 확률 96.8%로 예측하는 결과를 볼 수 있습니다.END
'IT > AI' 카테고리의 다른 글
[순환신경망] LSTM의 개념 (0) 2022.10.20 [Tensorflow, Keras] SimpleRNN 실습 (0) 2022.10.19 [순환신경망] RNN의 문제점 (기울기 소실, 기울기 폭주 = Gradient Vanishing & Exploding) (1) 2022.10.19 행렬 곱셈 vs 아다마르 곱셈 (Hadamard product vs Matrix multiplication) (0) 2022.10.18 [순환신경망] RNN의 개념 (0) 2022.10.18